前回に引き続き、研究論文執筆のために様々な自然言語処理を調査しており、自然言語処理の基礎ともいえるTF-IDFを使った重要単語抽出についてまとめてみました。古典的な手法ですが、とてもシンプルな計算式で求められるため、今も様々な分野で活用されています。
TF-IDFについて
TF-IDFとは文書中に含まれる単語の重要度を評価する手法の1つで、以下のような式で計算されます。
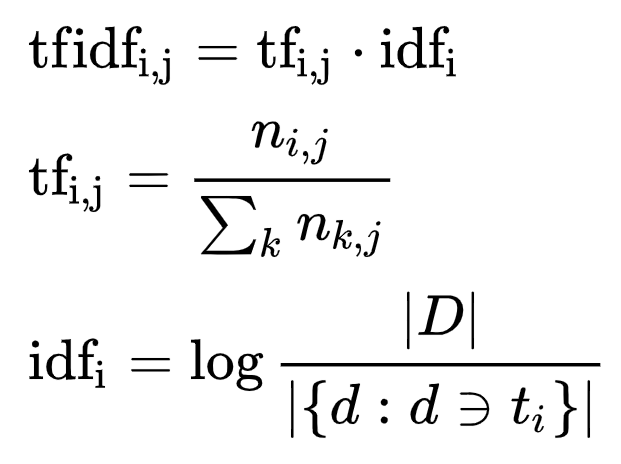
tf(i, j) = 文章jにおける単語iの出現頻度 / 文章における全単語の出現頻度の和
idf(i) = log(全文章数 / 単語iを含む文章数)
tfidf(i, j) = tf(i, j) * idf(i) = 単語の重要度
tf(Term Frequency)・・・単語の出現頻度(文章Aにおける単語xの出現頻度)
idf(Inverse Document Frequency)・・・逆文書頻度(一般的な用語程、idfの値が低くなり、重要な単語程高くなる)
tf(i, j) * idf(i) を求めると特定の文章に含まれる特定の単語の重要度が算出できるようになります。
例えば以下の3つの文章において各単語の重要度を求める場合、以下のように計算します。
文章A:[ブロンズ, シルバー, シルバー]
文章B:[ブロンズ, ゴールド],
文章C:[ブロンズ, ゴールド, プラチナ]
まず各単語の出現頻度 tf を求めます。
tf(i, j) = 文章jにおける単語iの出現頻度 / 文章における全単語の出現頻度の和
tf(ブロンズ, A) = 1/3 = 0.33 tf(シルバー, A) = 2/3 = 0.66 tf(ブロンズ, B) = 1/2 = 0.5 tf(ゴールド, B) = 1/2 = 0.5 tf(ブロンズ, C) = 1/3 = 0.33 tf(ゴールド, C) = 1/3 = 0.33 tf(プラチナ, C) = 1/3 = 0.33
次に逆文書頻度 idf を求めます。
idf(i) = log(全文章数 / 単語iを含む文章数)
idf(ブロンズ) = log2(3/3) = 0 idf(シルバー) = log2(3/1) = 1.58 idf(ゴールド) = log2(3/2) = 0.58 idf(プラチナ) = log2(3/1) = 1.58
最後に tfidf を求めます。
tfidf(i, j) = tf(i, j) * idf(i)
tf(ブロンズ,A) * idf(ブロンズ) = 0 tf(シルバー,A) * idf(シルバー) = 1.04 tf(ブロンズ,B) * idf(ブロンズ) = 0 tf(ゴールド,B) * idf(ゴールド) = 0.29 tf(ブロンズ,C) * idf(ブロンズ) = 0 tf(ゴールド,C) * idf(ゴールド) = 0.19 tf(プラチナ,C) * idf(プラチナ) = 0.52
tfidf の数値が高い単語程、重要な単語とされ、各文章で最も重要度の高い単語は以下の通りとなります。
文章A : シルバー
文章B : ゴールド
文章C : プラチナ
環境構築
実際に MeCab と Python を使用して重要単語の抽出するために環境構築を行います。
今回は AWS の EC2 (Ubuntu 20) 上に環境を構築します。
まず pip (Python 用パッケージマネージャ)をインストールします。
sudo apt-get update
sudo apt install python3-pipscikit-learn(Python 用機械学習用ライブラリ)をインストールします。
sudo pip3 install scikit-learnMeCab のインストールします。
sudo apt install mecab
sudo apt install libmecab-dev
sudo apt install mecab-ipadic-utf8Python用の MeCab ライブラリをインストールします。
sudo pip3 install mecab-python3
sudo pip3 install unidic-liteスクリプトの作成
tfidf_test.py というファイル名で、以下のようなスクリプトを作成します。
import MeCab
#指定したファイルを形態素解析し、単語を空白区切りで返す関数
def get_text(input_file_name):
with open(input_file_name, 'r', encoding='utf-8') as f:
text = f.read()
#MeCab を使用して形態素解析
mecab = MeCab.Tagger("-O chasen -d /var/lib/mecab/dic/ipadic-utf8/")
node = mecab.parseToNode(text)
words = []
#名詞、動詞、動詞である単語のみを抽出
while node:
if node.feature.split(",")[0] == u"名詞":
words.append(node.surface)
elif node.feature.split(",")[0] == u"形容詞":
words.append(node.feature.split(",")[6])
# elif node.feature.split(",")[0] == u"動詞":
# words.append(node.feature.split(",")[6])
node = node.next
#単語を空白で結合
text = ' '.join(words);
return text
from sklearn.feature_extraction.text import TfidfVectorizer
docs = [
get_text('sample1.txt'),
get_text('sample2.txt'),
get_text('sample3.txt'),
get_text('sample4.txt'),
get_text('sample5.txt'),
]
# tf-idfの計算(文書全体の50%以上で出現する単語は無視)
vectorizer = TfidfVectorizer(max_df = 0.5)
#tf-idf行列を取得
matrix = vectorizer.fit_transform(docs)
#単語リストを取得
print(vectorizer.get_feature_names())
words = vectorizer.get_feature_names()
for doc_no, vec in zip(range(len(docs)), matrix.toarray()):
print('doc_no:', doc_no)
for w_id, tfidf in sorted(enumerate(vec), key = lambda x: x[1], reverse=True):
word = words[w_id]
print('\t{0:s}: {1:f}'.format(word, tfidf))
サンプルの文章として以下の5社の企業理念を用意しました。
sample1.txt(トヨタの企業理念)
クリーンで安全な商品の提供を通じて、豊かな社会づくりに貢献し、国際社会から信頼される良き企業市民をめざしています。
sample2.txt(ANAの企業理念)
安心と信頼を基礎に、世界をつなぐ心の翼で夢にあふれる未来に貢献します。
sample3.txt(三菱商事の企業理念)
所期奉公(事業を通じ、物心共に豊かな社会の実現に努力すると同時に、かけがえのない地球環境の維持にも貢献する。)
sample4.txt(Amazonの企業理念)
お客様がオンラインで求めるあらゆるものを探して発掘し、出来る限り低価格でご提供するよう努めること。
sample5.txt(Googleの企業理念)
世界中の情報を整理し、世界中の人がアクセスできて使えるようにすることです。
スクリプトを実行すると以下のように出力されます。
python3 tfidf_test.py['お客様', 'かけがえ', 'こと', 'づくり', 'ない', 'もの', 'よう', 'アクセス', 'オンライン', 'クリーン', '世界', '世界中', '事業', '企業', '価格', '信頼', '努力', '商品', '国際', '地球', '基礎', '奉公', '安全', '安心', '実現', '市民', '情報', '所期', '提供', '整理', '未来', '物心', '環境', '発掘', '社会', '維持', '良い', '豊か', '限り']
doc_no: 0
社会: 0.455365
づくり: 0.282207
クリーン: 0.282207
企業: 0.282207
商品: 0.282207
国際: 0.282207
安全: 0.282207
市民: 0.282207
良い: 0.282207
信頼: 0.227683
提供: 0.227683
豊か: 0.227683
お客様: 0.000000
かけがえ: 0.000000
こと: 0.000000
ない: 0.000000
もの: 0.000000
よう: 0.000000
アクセス: 0.000000
オンライン: 0.000000
世界: 0.000000
世界中: 0.000000
事業: 0.000000
価格: 0.000000
努力: 0.000000
地球: 0.000000
基礎: 0.000000
奉公: 0.000000
安心: 0.000000
実現: 0.000000
情報: 0.000000
所期: 0.000000
整理: 0.000000
未来: 0.000000
物心: 0.000000
環境: 0.000000
発掘: 0.000000
維持: 0.000000
限り: 0.000000
doc_no: 1
世界: 0.463693
基礎: 0.463693
安心: 0.463693
未来: 0.463693
信頼: 0.374105
お客様: 0.000000
かけがえ: 0.000000
こと: 0.000000
づくり: 0.000000
ない: 0.000000
もの: 0.000000
よう: 0.000000
アクセス: 0.000000
オンライン: 0.000000
クリーン: 0.000000
世界中: 0.000000
事業: 0.000000
企業: 0.000000
価格: 0.000000
努力: 0.000000
商品: 0.000000
国際: 0.000000
地球: 0.000000
奉公: 0.000000
安全: 0.000000
実現: 0.000000
市民: 0.000000
情報: 0.000000
所期: 0.000000
提供: 0.000000
整理: 0.000000
物心: 0.000000
環境: 0.000000
発掘: 0.000000
社会: 0.000000
維持: 0.000000
良い: 0.000000
豊か: 0.000000
限り: 0.000000
doc_no: 2
かけがえ: 0.285112
ない: 0.285112
事業: 0.285112
努力: 0.285112
地球: 0.285112
奉公: 0.285112
実現: 0.285112
所期: 0.285112
物心: 0.285112
環境: 0.285112
維持: 0.285112
社会: 0.230026
豊か: 0.230026
お客様: 0.000000
こと: 0.000000
づくり: 0.000000
もの: 0.000000
よう: 0.000000
アクセス: 0.000000
オンライン: 0.000000
クリーン: 0.000000
世界: 0.000000
世界中: 0.000000
企業: 0.000000
価格: 0.000000
信頼: 0.000000
商品: 0.000000
国際: 0.000000
基礎: 0.000000
安全: 0.000000
安心: 0.000000
市民: 0.000000
情報: 0.000000
提供: 0.000000
整理: 0.000000
未来: 0.000000
発掘: 0.000000
良い: 0.000000
限り: 0.000000
doc_no: 3
お客様: 0.354602
もの: 0.354602
オンライン: 0.354602
価格: 0.354602
発掘: 0.354602
限り: 0.354602
こと: 0.286091
よう: 0.286091
提供: 0.286091
かけがえ: 0.000000
づくり: 0.000000
ない: 0.000000
アクセス: 0.000000
クリーン: 0.000000
世界: 0.000000
世界中: 0.000000
事業: 0.000000
企業: 0.000000
信頼: 0.000000
努力: 0.000000
商品: 0.000000
国際: 0.000000
地球: 0.000000
基礎: 0.000000
奉公: 0.000000
安全: 0.000000
安心: 0.000000
実現: 0.000000
市民: 0.000000
情報: 0.000000
所期: 0.000000
整理: 0.000000
未来: 0.000000
物心: 0.000000
環境: 0.000000
社会: 0.000000
維持: 0.000000
良い: 0.000000
豊か: 0.000000
doc_no: 4
世界中: 0.694134
アクセス: 0.347067
情報: 0.347067
整理: 0.347067
こと: 0.280011
よう: 0.280011
お客様: 0.000000
かけがえ: 0.000000
づくり: 0.000000
ない: 0.000000
もの: 0.000000
オンライン: 0.000000
クリーン: 0.000000
世界: 0.000000
事業: 0.000000
企業: 0.000000
価格: 0.000000
信頼: 0.000000
努力: 0.000000
商品: 0.000000
国際: 0.000000
地球: 0.000000
基礎: 0.000000
奉公: 0.000000
安全: 0.000000
安心: 0.000000
実現: 0.000000
市民: 0.000000
所期: 0.000000
提供: 0.000000
未来: 0.000000
物心: 0.000000
環境: 0.000000
発掘: 0.000000
社会: 0.000000
維持: 0.000000
良い: 0.000000
豊か: 0.000000
限り: 0.000000
各社の重要度の高い単語(上位5つ)は以下の通りとなりました。
トヨタ
社会: 0.455365
づくり: 0.282207
クリーン: 0.282207
企業: 0.282207
商品: 0.282207
ANA
世界: 0.463693
基礎: 0.463693
安心: 0.463693
未来: 0.463693
信頼: 0.374105
三菱商事
かけがえ: 0.285112
ない: 0.285112
事業: 0.285112
努力: 0.285112
地球: 0.285112
Amazon
お客様: 0.354602
もの: 0.354602
オンライン: 0.354602
価格: 0.354602
発掘: 0.354602
世界中: 0.694134
アクセス: 0.347067
情報: 0.347067
整理: 0.347067
こと: 0.280011
それなりに重要と思われる単語が抽出できていますが、精度を上げるにはサンプル数を増やし、一般的な単語をフィルタリングする必要があると思われます。