最近仕事でカラムストアインデックスについて調べる機会があったので、自分なりにまとめてみました。
1. 概要
カラムストアインデックス(列ストアインデックス)とは SQL Server 2012 に搭載された新しいインデックス方式です。主に大量のデータを高速に処理するために開発されました。通常のB木インデックスでは、ページと呼ばれる 8KB のブロックの中に、表形式で定義したテーブルの各行をひとつの単位として格納していますが、カラムストアインデックスでは列ごとにデータをひとつのまとまりとして管理します。
カラムストアインデックスの最大のメリットは、クエリで必要としているデータのみを操作できるため、パフォーマンスの向上が期待できる点です。
SQL Server 2012 のカラムストアインデックスは非クラスタ化カラムストアインデックスで、読み取り専用テーブルのみで利用可能であるという大きな制約がありましたが、SQL Server 2014 からは、更新可能なクラスタ化カラムストアインデックスが利用可能となりました。
カラムストアインデックスは、大量のデータが格納されたテーブルのグルーピングや集計を行うクエリを実行する際に効果を発揮するとされています。
またインデックスには、「クラスタ化インデックス」と「非クラスタ化インデックス」の2種類あります。「クラスタ化インデックス」は、実データを保持しますが、「非クラスタ化インデックス」はデータへのポインタを保持しています。「クラスタ化インデックス」は各テーブル対して1つのみ作成可能です。
「通常のインデックス」、「カラムストアインデックス」それぞれに「クラスタ化インデックス」と「非クラスタ化インデックス」が存在します。よってインデックスの種類は以下の4種類となります。
1. クラスタ化インデックス
2. 非クラスタ化インデックス
3. クラスタ化カラムストアインデックス
4. 非クラスタ化カラムストアインデックス
今回調査、検証を行ったのは「クラスタ化カラムストアインデックス」となります。以降「クラスタ化カラムストアインデックス」を「カラムストアインデックス」と略します。
2. カラムストアインデックスの作成
カラムストアインデックスは以下の構文で作成可能です。
CREATE CLUSTERED COLUMNSTORE INDEX インデックス名
ON テーブル名
※ CLUSTERED を省略した場合、NONCLUSTERED (非クラスタ化インデックス)として作成されます。
※ クラスタ化カラムストアインデックスの場合、列名の指定はできません。全ての列に対してインデックスが作成されます。
※ カラムストアインデックスはEnterprise、Developer、および Evaluationエディションでのみ利用可能です。Standard、Web、Express エディションでは使用できません。
3. カラムストアインデックスの制約
クラスタ化カラムストアインデックスはテーブル内にクラスタ化インデックスと合わせて1つしか作成できません。またプライマリーキーはクラスタ化インデックスに該当するため、カラムストアインデックスとの共存はできません。
各インデックスの同時利用の可否は以下の通りです。
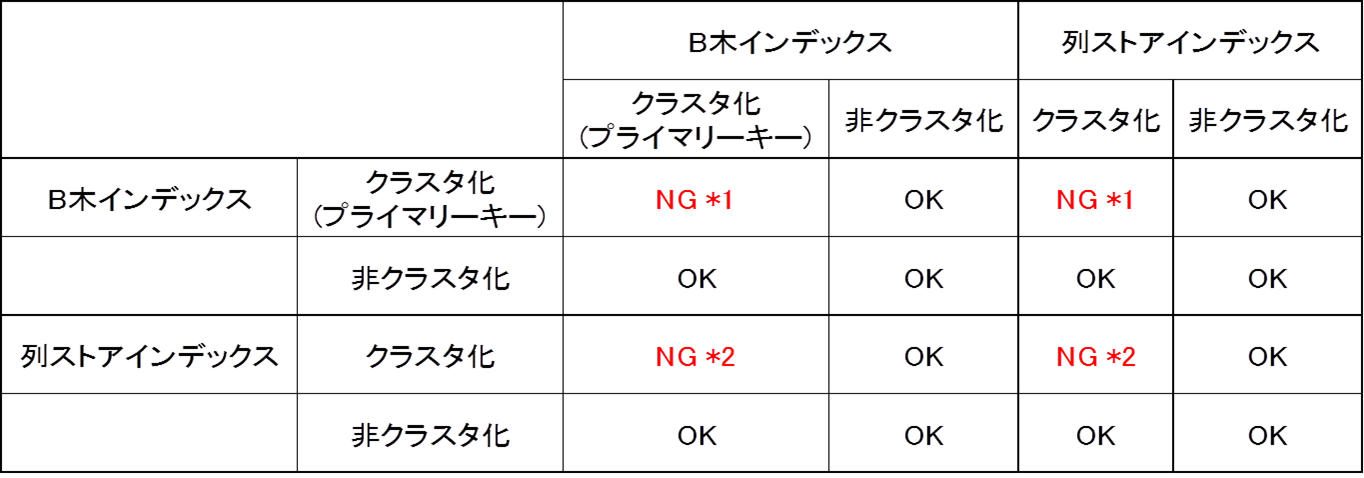
作成時に表示されるエラーメッセージ
*1 …テーブル ‘data_btree_index’ にはクラスター化インデックスを複数作成できません。既存のクラスター化インデックス ‘ix_btree_index’ を削除してから別のクラスター化インデックスを作成してください。
*2 …テーブル ‘data_columnstore_index’ には複数のクラスター化インデックスを作成できません。’with (drop_existing = on)’ オプションを使用して新しいクラスター化インデックスを作成することを検討してください。
4. 検証方法
通常のB木インデックスとカラムストアインデックス用のテーブルを作成後、それぞれに大量のダミーデータを追加し、SQL Server Profiler を使用してクエリの実行時間の計測を行いました。
検証PC : iMac Retina 5K, Windows 7, Intel Core i5 3.5Ghz, RAM : 16GB
具体的な手順は以下の通りです。
1. テーブルを2つ作成し、各テーブルに同一の条件で大量のダミーデータを作成します。

2. テーブル1に対しては通常のインデックス(B-Tree)、テーブル2に対してカラムストアインデックスを作成します。

3. 各テーブルに大量のダミーデータ追加し、SQL Server Profilerを使用して実行時間を計測し、比較します。

その他、テーブル結合、レコード追加のパフォーマンス検証も合わせて行いました。
5. 検証結果
検証した結果は以下の通りです。
◆ レコード数1万 / カラム数28の場合
単位 : ミリセカンド

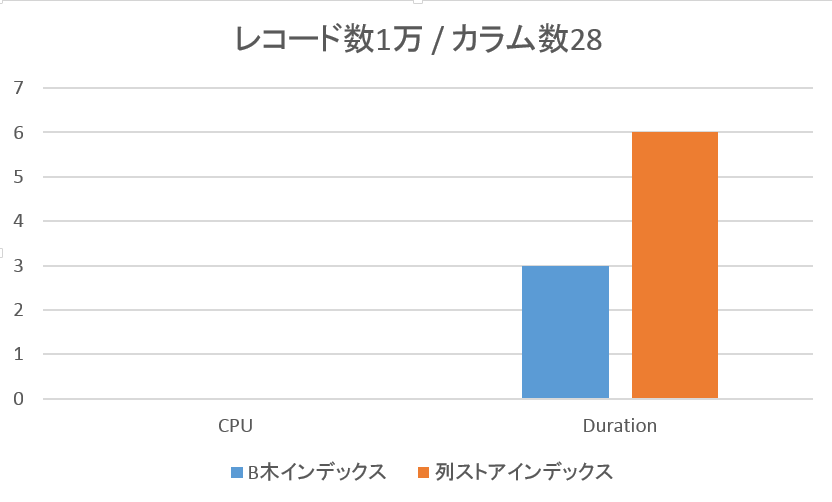
従来のB木インデックスの方が高いパフォーマンスを示しています。
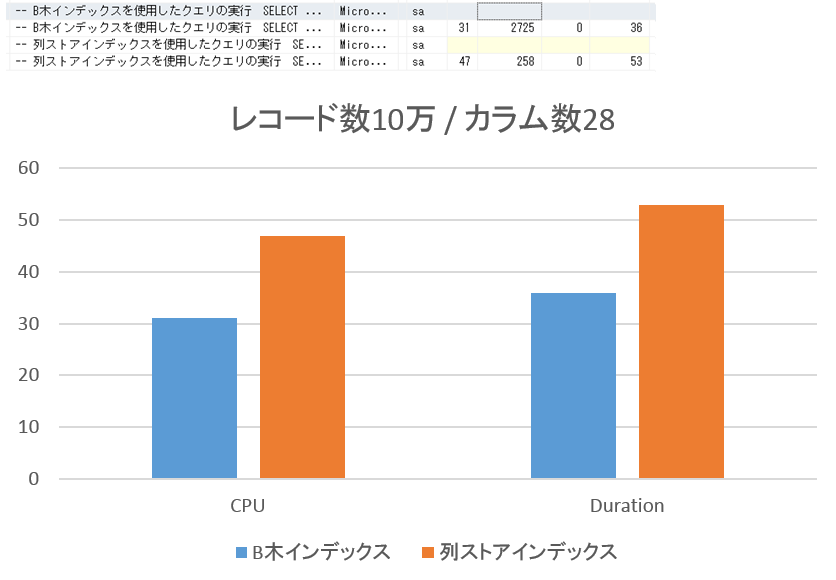
◆ レコード数10万 / カラム数28の場合

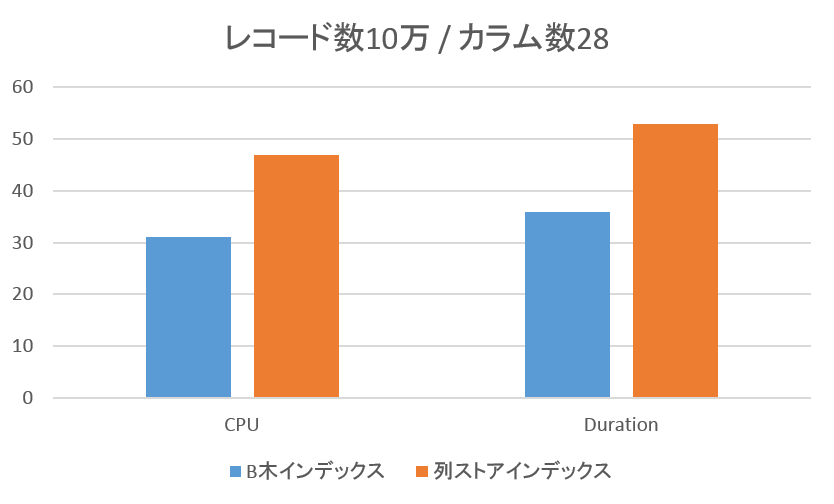
従来のB木インデックスの方が高いパフォーマンスを示しています。
◆ レコード数100万 / カラム数28の場合
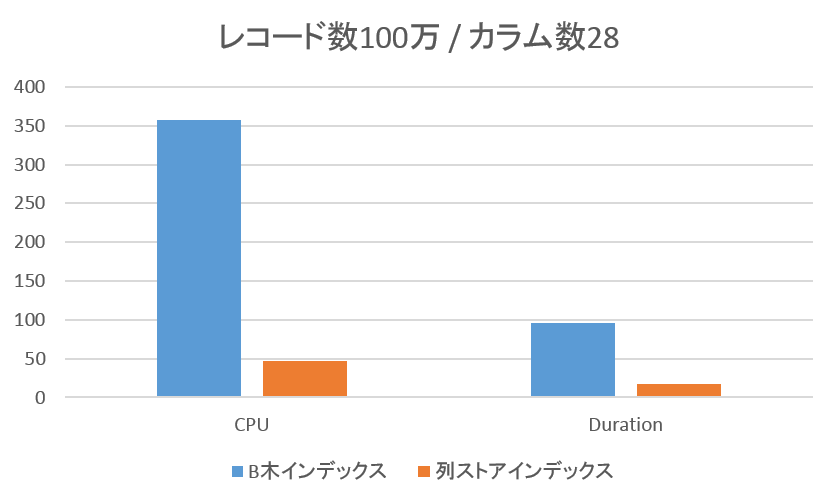
カラムストアインデックスの方が非常に高いパフォーマンスを示しています。
◆ レコード数100万 / カラム数2の場合

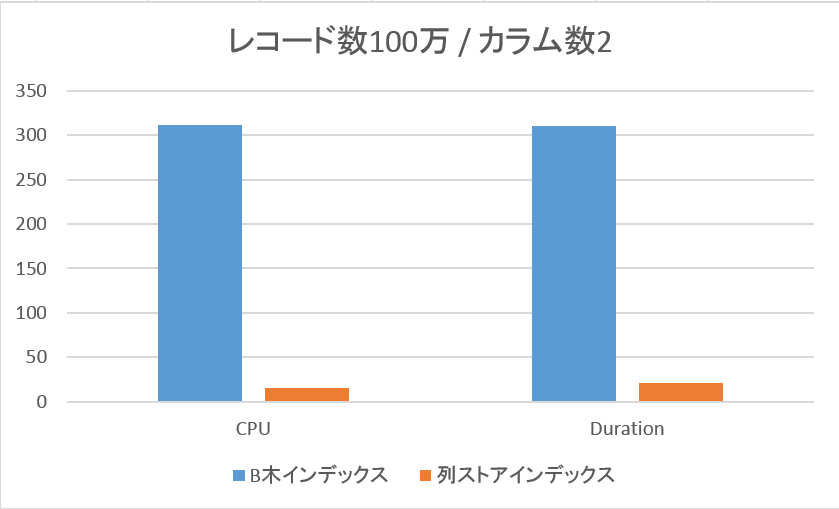
カラムストアインデックスの方が非常に高いパフォーマンスを示しています。
6. 検証結果 (テーブル結合)
B木インデックスを追加したデータ系テーブル(レコード数:100万)、マスタ系テーブル(レコード数:10万)、カラムストアインデックスを追加したデータ系テーブル(レコード数:100万)、マスタ系テーブル(レコード数:10万)を用意し、テーブルを結合するクエリを実行し、パフォーマンスの検証を行いました。
テーブルの結合の組み合わせは以下の通りです。
データ:B木インデックス ✕ マスタ : B木インデックス
データ:B木インデックス ✕ マスタ : カラムストアインデックス
データ:カラムストアインデックス ✕ マスタ : B木インデックス
データ:カラムストアインデックス ✕ マスタ : カラムストアインデックス
◆ 実行したクエリ
◆ 実行結果

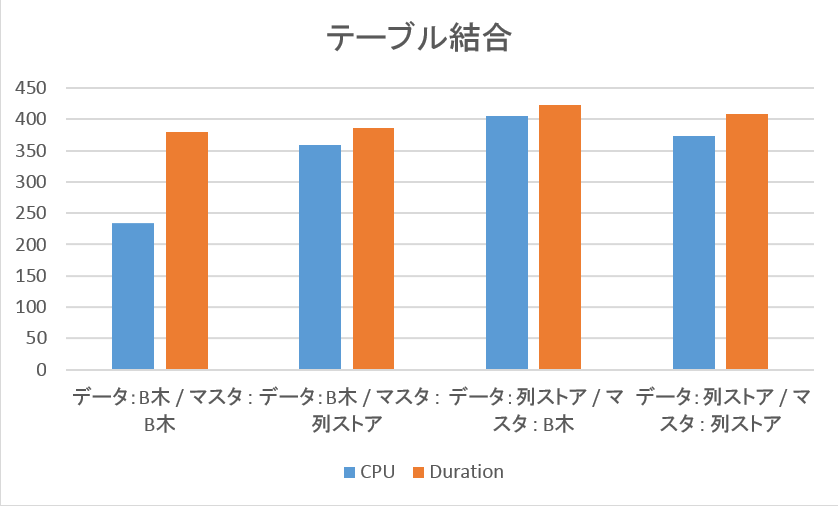
大きなパフォーマンスの差異は認められませんでした。
7. 検証結果 (レコード追加)
Bインデックスを追加したテーブル、カラムストアインデックスを追加したテーブル、それぞれに対して1000件のレコードを追加し、パフォーマンスの検証を行いました。
各テーブルには事前に10万件のレコードを追加しております。

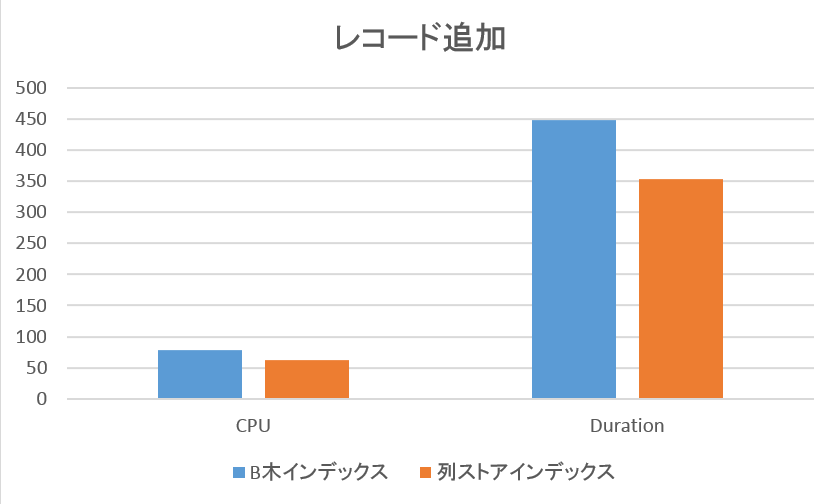
大きなパフォーマンスの差異は認められませんでした。
8. まとめ
カラムストアインデックスは、レコード数が1万件など比較的少ない場合には、ほとんど効果はありませんでしたが、レコード数が100万件など大量のデータが格納されたテーブルに対してグルーピングや集計を行う場合には、顕著なパフォーマンスの向上が確認できました。またテーブルのカラム数の少ない場合にもカラムストアインデックスの大きな効果が確認できました。
ただし、カラムストアインデックスは他のクラスタ化インデックスや、プライマリーキーと共存できないなどの制約があります。またテーブルの結合、レコードの追加についてはパフォーマンスに特に大きな差は確認できませんでした。
このことから100万単位以上のデータの格納が想定され、かつプライマリーキーを必要としないテーブルに限定して「カラムストアインデックス」を使用することが望ましいと思われます。
具体的にはユーザマスタ、商品マスタなどマスタ系テーブルではなく、注文履歴などを格納するトランザクション系のテーブルなどに利用するのが望ましいと思います。